shell码表爬虫
先说思路,将码表中的单字提出来,作为参数传给wget下载
1.整理码表,首先剔除原码所有的词,只留下单字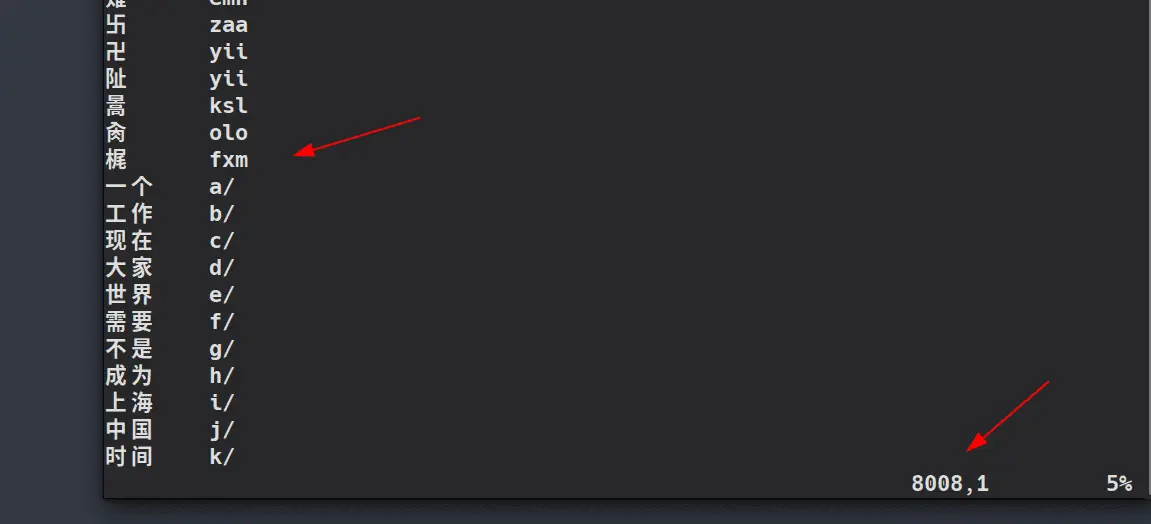
vim的批量删除行 :8008,$d
$是文末的意思,d是删除,这里的意思是删除从8008到文末的所有行
剪切第一个值 cut -f1 smzmuke.txt > 1
用 -f 来设置我要提取的第一个域,然后重定向的1这个文件
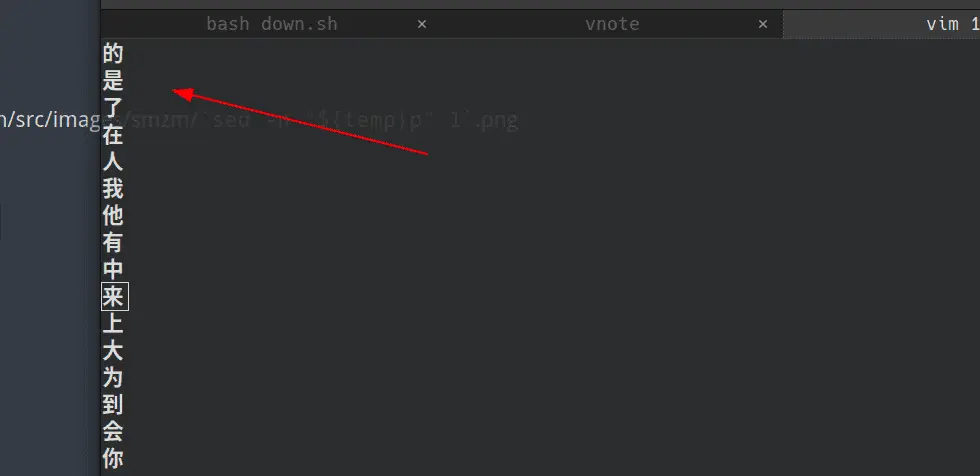
输出第一行 sed -n ‘1p’ 1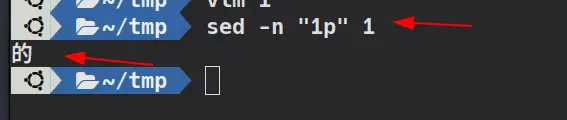
-n选项经常和 p 配合使用,其含义就是,输出那些匹配的行,输出“1”文件中的第一行
到这里前期工作就已经完成了,接下来写爬虫吧
2.爬虫源码
1 |
|
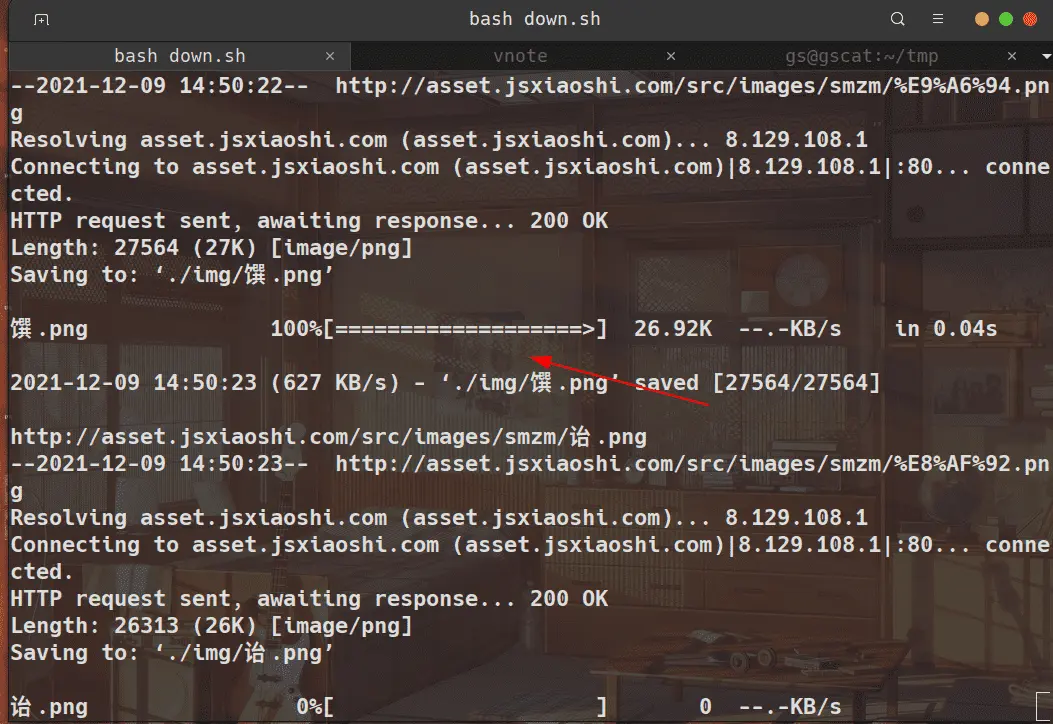
看来正常的跑起来了