为什么要引入Cache?
随着工艺和设计的演进,CPU计算性能其实发生了翻天覆地的变化,但是DRAM存储性能的发展没有那么快。所以引入了一个中间缓冲区域cache
Cache 按照数据类型可划分为 I-Cache 与 D-Cache。其中 I-Cache 负责放置指令, D-Cache 负责方式数据。两者最大的不同是 D-Cache 里的数据可以写回, I-Cache 是只读的。
Cache为什么能提高代码运行效率?
Cortex-M7的I-Cache和D-Cache都是紧耦合在CPU内部的,访问延迟基本就是一个CPU时钟周期,可以认为CPU与cache是同频的
cache并不是由⽤户⼿动选择存⼊哪些数据的,⽽是由硬件或底层机制⾃动管理的。cache依赖局部性原理,包括时间局部性和空间局部性
时间局部性:部分代码或者变量可能会被重复访问
空间局部性:需要访问的数据在内存中可能是连续存放的
当CPU访问cache过的Memory时,由于cache可以缓存memory的内容,这样CPU访问memory就会变成访问cache,从而提升性能
cache数据结构
Cache并不是简单的复制memory的内容,而是由下面三个部分组成
1.Tag标记这行cache数据对应的memory范围
2.Data数据块(cache line):具体缓存的数据内容
3.Valid/Dirty位:标记cache line是否有效/标记cache中的数据已修改但未写回memory
访问过程: Hit vs Miss
CPU访问某个地址时:
1.从地址中取出Tag,与cache中的tag比较
2.如果命中(hit),则直接返回cache中的数据
3.如果缺失(miss),需要从memory把数据加载到cache,再提供给CPU
cache 写数据策略
- CPU hit
1.Write through(WT): CPU向cache中写入数据时,同时向momory中也写一份,使cache和memory的数据保持一致。每次都要访问memory,速度相对比较慢
2.Write back(WB):CPU更新cache时,只是把更新的cache区标记一下,并不同步更新memory,只是在cache区要被新进入的数据取代时,才更新memory。很多时候cache存入的是中间结果,没有必要同步更新memory,CPU执行的效率提高 - 若CPU miss
1.Write allocate :先把要写的数据载入到cache中,写cache,然后再通过flush方式写入到memory中。
2.No write allocate:直接把要写的数据写入memory中
cache 读数据策略
-若CPU hit
CPU 直接从cache中读取数据
-若CPU miss
Read through:CPU直接从Memory中读取数据
Read allocate: cache先缓存当前memory,CPU再从cache中读取数据
对cache的操作
1.Invalidate
清除cache line的valid bit有效位,使数据失效,达到清除数据的功能。比如在上电或者重置操作后,cache的内容是未定义的,此时它的valid bit为0
2.Clean
某个cache line中的dirty bit为,说明line中的数据与内存中的不一致。Clean操作使cache中的内容写入memory。此操作仅适用于写回策略(WB)的数据缓存
cache的操作示例
举个例子:
在开启cache后,如果SPI使能了DMA,需要对SPI传输的RX buff和 TX buff做怎样的操作呢?
传输前:
CPU写的tx buff的数据还在cache中,需要先通过clean将数据同步到sram中,确保DMA能够取到最新的数据
1 | SCB_CleanDCache_by_Addr((uint32_t*)tx_buff, size); |
传输后:
DMA已将rx buff的真实值写入在sram中,但是cache中可能还是旧值,需要invalidate,丢弃掉旧值,让CPU读rx buff时直接从加载
1 | SCB_InvalidateDCache_by_Addr((uint32_t*)rx_buff, size); |
内存保护单元MPU(memory protection unit)
MPU可以通过设置region来给不同区域配置不同的cache策略,每个Region为基地址与 region size。其中基地址要求 32 字节对齐,即要求 Base_address % 32 == 0。Region size 要求为32字节的整数倍,最小为32字节,最大为65536字节。
可以配置16的内存区域,,每个区域又可以配置8个子区域。区域之间可以重叠也可以嵌套,优先级0-15,数字越大,优先级越高。
Memory属性配置
TEX 与C,B共同控制Memory属性,S表示Shareable,根据不同的内存属性有着不同的作用域。设置 shareable 表示该存储块可以被多个主设备访问,当配置 Shareable时,该区域的数据是不会使用cache的,效果跟 write through 一样。
如果 Non-shareable, 一般指被本地 CPU 访问
下面是MPU配置中最重要的表格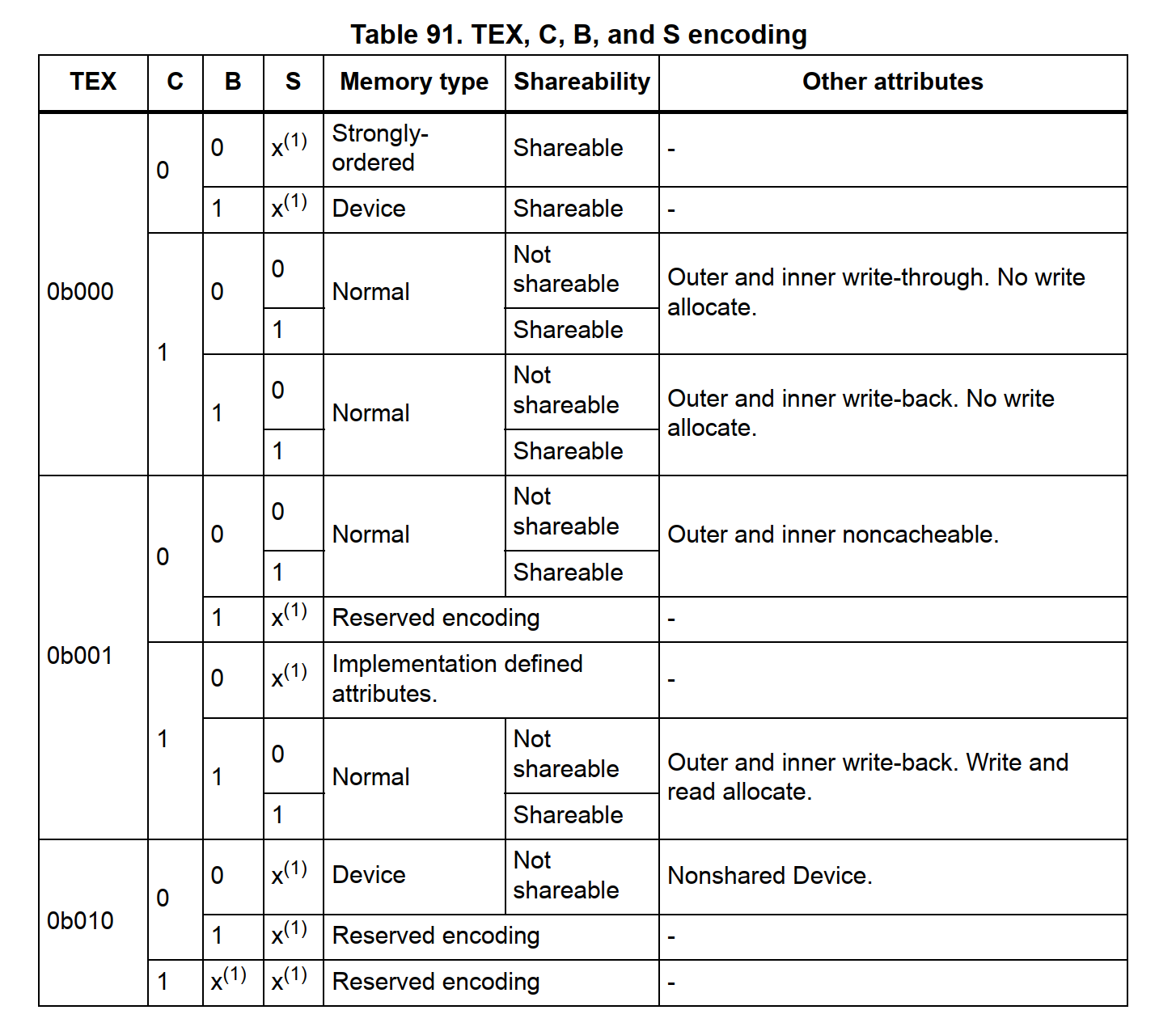
ARMv7 默认的 Memory Map 属性如下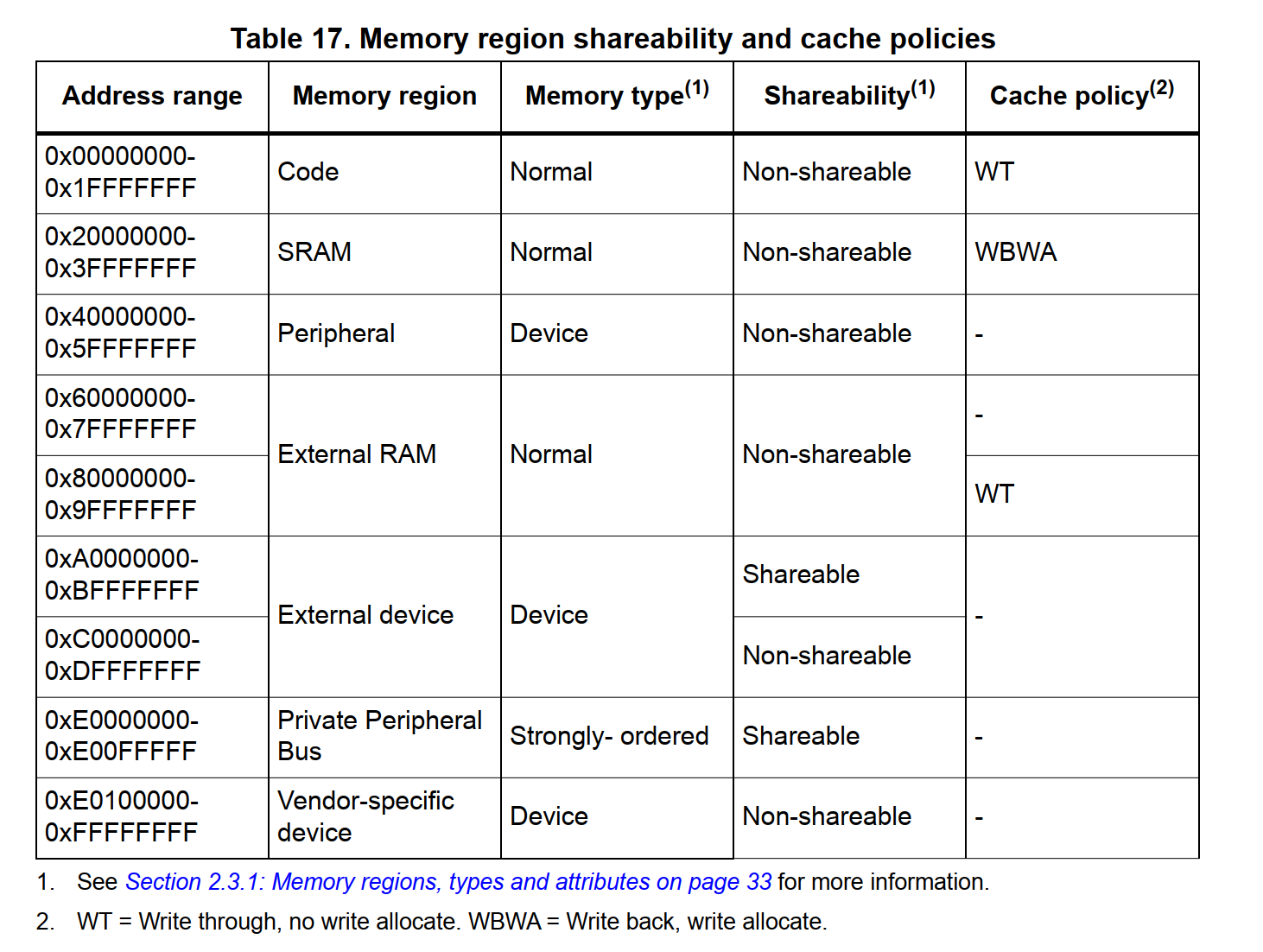
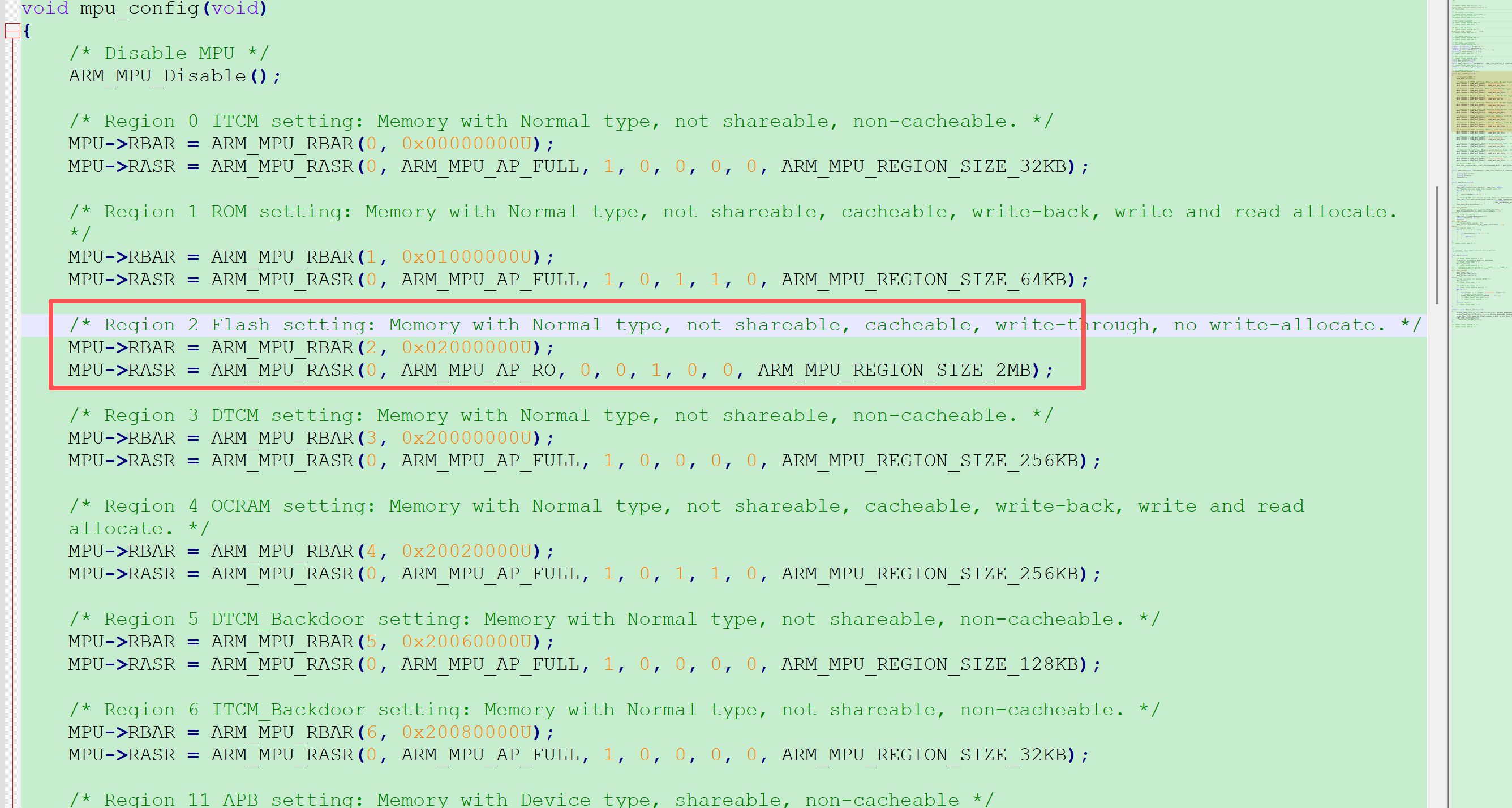

PRIVDEFENA=1:特权模式可访问未配置区域,适合需要保留灵活访问权限的场景。
PRIVDEFENA=0:强制所有访问必须符合 MPU 配置,适合高安全性要求的系统。
如果开启cache后,发现会概率性报ibuserr的错误,并且错误的地址不太固定,可以尝试将PRIVDEFENA设置为0。避免对这些未配置的区域进行非预期操作导致错误。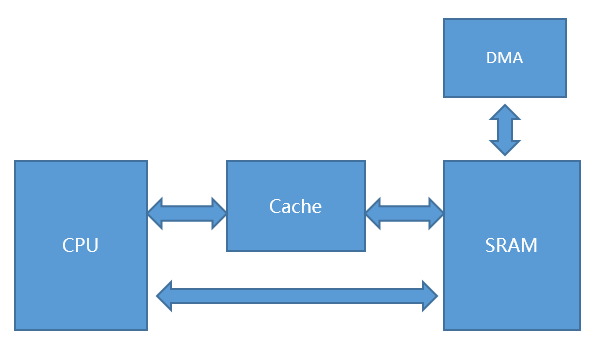
参考资料
ST AN4838
DDI 0403E
DM00237416
TB3195 管理基于 Cortex®-M7 的 MCU 的高速缓存一致性